Tsuika

Table of contents
The name “Tsuika” comes from a Japanese word meaning “addition”, symbolizing the act of adding something new. There’s no elaborate backstory behind it—I simply thought it sounded cool, and since none of my projects had used Japanese references before, I figured the first time’s the charm.
Tsuika started as a bookmark manager I built for myself to experiment with new tech stacks I’d recently learned, particularly writing my own back-end with PostgreSQL. Like many engineers, I believe the best way to solidify knowledge is to build something practical with it. Beyond the learning aspect, I’ve grown to love creating my own tools because it’s incredibly fun and deeply satisfying. For instance, I use a custom-configured desktop environment, have built my own desktop components, developed several CLI apps, and worked on various other projects. Initially, my goal was to learn, but over time, the joy of creating useful tools (at least for me) took hold, and I’ve become hooked on building my own solutions.
Why another bookmark manager?
My choices are not based on fundamental necessity of what world wants, I wanted a good looking decent bookmark manager along with the features I want. Whenever I choose software there’s are some basic requirements of mine…
- Not 90s nor cultured UI
- Responsive and optimized
- Has a android app, web-app and desktop app (basically cross platform)
These are my 3 basic requirements when picking a software, but when It came to features I wanted for my own bookmark manager, the list is simple…
- Minimal UI
- Optimized (not ranting of granny’s PC, it’s about server load, always!!)
- PWA (cause I can’t build desktop or mobile apps yet)
- Vault for storing secret bookmarks with E2E encryption
- Must be able to share publicly with or without password protection
- Some collaborative features with authorization
- Other basic features that are not worth highlighting but must have eg. tags, search, filter…
Simple list; and most popular bookmark manager do have them, still why build one? And the answer is simple, see this as a another TODO app or maybe add it to a list of ‘awesome list’ choices along with them. It’s my own bookmark manage,r for me not a SASS (not right now, maybe never).
Let’s talk about stack
It’s always very important to keep your stack list static beforehand, it’s not something anyone would get at the beginning but have to experience why. Well discuss gradually why it’s important.
Backend
I decided to work on this project to build my first proper back-end. While I’ve followed YouTube tutorials to learn, I don’t consider those exercises “building something” unless they’re useful to me. If it doesn’t serve a practical purpose, I don’t count it as a project. Here’s the tech stack I used:
- Hono: Backend framework, like express but better
- Drizzle ORM, like Prisma but better and lightweight
- Neon Hosted PostgreSQL database
- Better Auth: Authentication framework
- https://resend.com + React Emails: Electronic mail sending service
- ImageKit: Image hosting service
To some, this stack might seem bleeding-edge; others might label me a “Superior Stack Syndrome” guy. They’re not entirely wrong. Why choose Drizzle over Prisma or Hono over Express.js? These tools may be newer, but this is my personal project—a space for experimentation, but apart from that I did pick the right tool for the job. My goal was to build a serverless app to host on platforms like Vercel or Cloudflare Workers/Pages, avoiding the need to manage my own server instance.
Neon’s serverless PostgreSQL and generous free tier made it an easy, almost random choice. Drizzle supports serverless out of the box with robust performance, unlike Prisma’s alpha beta serverless feature, despite Prisma being more battle-tested. As for Better Auth, I preferred it over services like Clerk or Auth0 to avoid relying on multiple external providers (Neon for the database, another for authentication). This decision proved 100% correct, and I have no regrets. Plus, the app is built to work with raw PostgreSQL 17, so it’s not strictly tied to Neon.
Frontend
Choosing the front-end framework was a straightforward decision. I asked myself a few questions: Do I want a fully client-side app or one with server-side rendering? If fully client-side, React with Vite is the way to go; if not, Next.js is the better choice. That was the main decision point. There’s also SvelteKit, which brings another question: Do I want to build quickly with what I know or experiment with something new? For me, the answer was clear—stick with React, which I know well and offers the best job opportunities. Mastering it over time is better than just being familiar with it, so the choice was easy. Now, let’s move to the bullets…
- React: Frontend lib
- Vite Bundler
- Bun: Install (cause fucking fast)
- Tanstack Router: Routing, alternative to good old react-router
- Tanstack React Query: Better than ‘useState’ and ‘useEffect’ hell
- ShadCN/UI: User Interface components
- TailwindCSS, ESLint an other default stuff
Development
Like many developers, I found the start of this project exciting and fun, the middle a bit depressing with self-doubt, and now, nearing the end, I’m happy again because I’ve accomplished the most important parts. Here’s a brief overview of the development process.
Preparing the Ingredients
Setting up the project took significant time—selecting dependencies, linters, and formatters was a major step. Initially, I chose Biome.js as a replacement for ESLint and Prettier, but I later switched back to ESLint and Prettier. While Biome.js worked fine, most frameworks and libraries didn’t support its custom rules. Since I’m not yet an expert in React Query or TanStack Router, I needed those custom ESLint rules as “training wheels” to avoid issues like memory leaks, infinite loops, or those frustrating “it’s not working, and I don’t know why” moments. For the back-end, I stuck with Biome.js for linting and formatting, as it’s less chaotic than the React ecosystem.
I also put new players in to the game such as ‘lefthook’, which is a really really good way to do pre-commit hooks, super fast to setup than husky and ‘commit-lint’ as I prefer conventional commits over any other format.
Structure
The development process started slowly because TanStack React Router was new to me, and I was still getting comfortable with React Query. I focused heavily on structure and naming conventions, such as adopting kebab-case (inspired by ShadCN/UI) over PascalCase for all my projects. This isn’t about one being better, it’s about maintaining consistency from the start. Organizing files and folders, like separating hooks, queries, lib, and utils, is also critical. These details vary by language and may seem minor, but they’re essential for long-term maintainability, even if they’re rarely discussed. In programming, there’s no such thing as small, medium, or big problems, every issue is significant
depending on the perspective.
UI
When it came to the UI, I noticed many experienced full-stack developers prioritize functionality over design, which makes sense since an app is useless without working features. However, I struggle to feel progress if the UI looks unappealing, after all, building should be fun! This used to be a challenge until TailwindCSS gained popularity, enabling easy copy-paste UI components. Now, ShadCN/UI is my go-to lib because it’s fast, minimal, and visually appealing, aligning perfectly with my preferences.
CRUD/API Calls
Let’s talk about bored to death part: CRUD operations. After the initial implementation, I find them tedious; mostly copying and pasting old code with minor tweaks. I’ve often wondered, “Should I reuse the same logic and just tweak it with parameters and a switch case?”, no, never do that, I’ve learned the hard way that this leads to an unmaintainable spiral. My instinct to “not waste resources” makes me obsess over minimizing API calls, which can be stressful. Thankfully, React Query simplifies this. By leveraging mutations and optimistic updates through cache manipulation, I can make the app reactive without relying on useState or useEffect. This approach also eliminates the need for third-party state management libraries. For these reasons, I’m committed to using React Query in all my projects. If you don’t need advanced cache manipulation, simple mutations are enough. React Query makes it effortless to handle states like loading, pending, and isFetching without custom logic. What seems straightforward at first, building your own loading and fetching logic often spirals into a debugging nightmare, requiring more than thousands commits to fix. Using a proven solution like React Query is usually the smarter choice.
Security
I take security seriously, but I’m not extreme, I aim for a balance between robust security and ease of use to avoid driving myself insane. Following this approach, I implemented essential security features throughout the app, including two-factor authentication (2FA). As mentioned earlier, I also added a “secured folder” system where users can store bookmarks with password protection, fully encrypted end-to-end (E2EE) on the client side. For encryption, I initially used libsodium, but its heavy reliance on WebAssembly (WASM) led to larger bundle sizes and occasional bundler errors about Node environment compatibility, despite it working fine. I switched to noble, which is lightweight and eliminates those issues, though it’s noticeably slower than libsodium. Since I learned cryptography basics in just 2-3 days before implementing, I followed key best practices but you guys are always welcome make the whole flow robust, cause you never know.
Beyond the subject secured folder, users can create bookmark collections (or folders) and make them public with shareable links. These public folders support optional password protection, but it’s not using fancy E2EE, it relies on JWT for password verification. Why? Well, let’s talk about rich link previews, because who doesn’t love a shiny thumbnail and snappy description when sharing a link? To make those previews happen, pasted links need to hit my server for scraping, since client-side scraping gets slapped with CORS. So, for the Secured Folder to stay truly E2EE, I made a tough call: users have to manually enter the title, description, thumbnail, you name it. Yeah, it’s a bit of a pain, but it’s the only way to keep the encryption promise airtight. No server snooping, no compromises. And to be honest that’s how privacy works, it’s not convenient at all, never. They only way would be host your own server for scrapping, and In future I might add a toggle option something like “Enable rich link previews” with a fair warning.
On the back-end, I follow standard security practices, one of which I’m particularly proud of: I never expose raw numeric IDs. Instead, I use a public_id field, generated with nanoid, to share externally. This decision wasn’t straightforward. Initially, I considered using UUIDs as primary keys to avoid exposing numeric IDs, but after reading several blogs, I learned that UUIDs can significantly impact B-Tree performance in SQL databases over time. A B-Tree is an algorithm that helps SQL efficiently determine where to insert new rows and search for existing ones without scanning from the beginning. UUIDs, due to their randomness, disrupt this efficiency, leading to performance issues, especially for joins and searches. And SQL is all about joins and relations and searching indexing, so you can’t mess with that.
Along the way, I stumbled across a whole zoo of ID types I didn’t even know existed: UUIDv4, UUIDv7, Snowflake IDs, GUIDs, KSUIDs, XIDs—you name it, it’s out there. Each has its quirks, but none felt like the perfect fit for my use case. Then I came across some stellar advice from blogs, including one from PlanetScale (shoutout to them!), which inspired my current setup: stick with good ol’ numeric IDs as primary keys for performance but generate a public_id with nanoid for external exposure. It’s the best of both worlds—SQL stays happy with fast B-Tree operations, and my APIs stay secure by hiding those predictable numeric IDs.
You might think, “Why bother with all this ID nonsense?” But trust me, sweating the small stuff like this is what separates a solid app from one that gets pwned—or worse, one that nobody trusts enough to use. It’s the kind of attention to detail that makes hiring managers sit up and take notice. So, what do you think? Got any ID-generation tricks or backend security tips to share? I’m all ears!
Things I may or may not regrade in future
I went all out with this project ha ha, I split it into five repos: Backend, Frontend, Email Templates, Landing/Server Stuff, and a Browser Extension. Overkill? Maybe. But it felt like the right call to keep things modular and sane. In hindsight, though, I’m wondering if I should’ve gone monorepo with something like TanStack Start or Next.js, powered by Turborepo. Why? Because redeclaring types for data bouncing between backend and frontend is a total pain. If I’d used tRPC, I could’ve saved myself that headache. Lesson learned—next project, maybe! Then there’s the licensing saga. Oh man, licensing gave me nightmares. I read blogs, watched videos, even begged AI agents for clarity, but it’s still a blur. My backend’s AGPL-v3 (100% my code, full control), but the frontend’s MIT because I used MIT-licensed components like ShadCN. I was paranoid about MIT components clashing with AGPL-v3, still not sure if that’s a real issue. Anyone got a law degree to help me out? Well, At the time, this approach felt perfect, and I was excited to focus on building rather than overthinking. They say if it’s too complicated; just pick MIT, it’s literally shorter than my blog’s summary, Maybe, I should have listened to them.
The browser extension was a critical part of the project and a tough but fun challenge, especially grappling with service workers. I used WXT, a Next.js like framework for browser extensions, which was a great experience compared to Plasmo, which I found lacking. The extension’s functionality is straightforward, logging in and creating bookmarks, nothing revolutionary, so I won’t dwell on it. I also built a Node module, published on npm.js as tsuika-email-templates, which handles transitional emails using react-email. I created this module to avoid including react, react-dom as dependencies in my back-end’s package.json, which felt weird and wrong as hell.
Always Plan First
Planning often feels underrated, especially for personal projects where it’s impossible to map everything out upfront. Unlike working on someone else’s project, where rules and requirements are clearly defined, personal projects can be chaotic to plan. Let me explain with an example. As I mentioned earlier, I decided not to expose raw id fields and instead use public_id. Initially, I was using only id, but when I changed my approach, I had to refactor the entire codebase. Similarly, I revamped how I handle errors. At first, I used throw new HttpError, but later I created a throwError function that takes parameters like string code, status number, error source, and message.
Error definitions in on place
const ERROR_DEFINITIONS = {
ALREADY_EXISTS: { code: "ALREADY_EXISTS", status: 409 },
CONFLICT: { code: "CONFLICT", status: 409 },
UNAUTHORIZED: { code: "UNAUTHORIZED", status: 401 },
REQUIRED_FIELD: { code: "REQUIRED_FIELD", status: 400 },
};And a function to bind em together
function throwError(key: ErrorCodeKey, msg: string, src: string): never {
const def = ERROR_DEFINITIONS[key];
throw new ApiError(def.status, msg, def.code, src);
}
throwError("NOT_FOUND", "User profile not found", "profiles.get");This standardized approach was much more convenient and consistent, so I adopted it throughout the project.
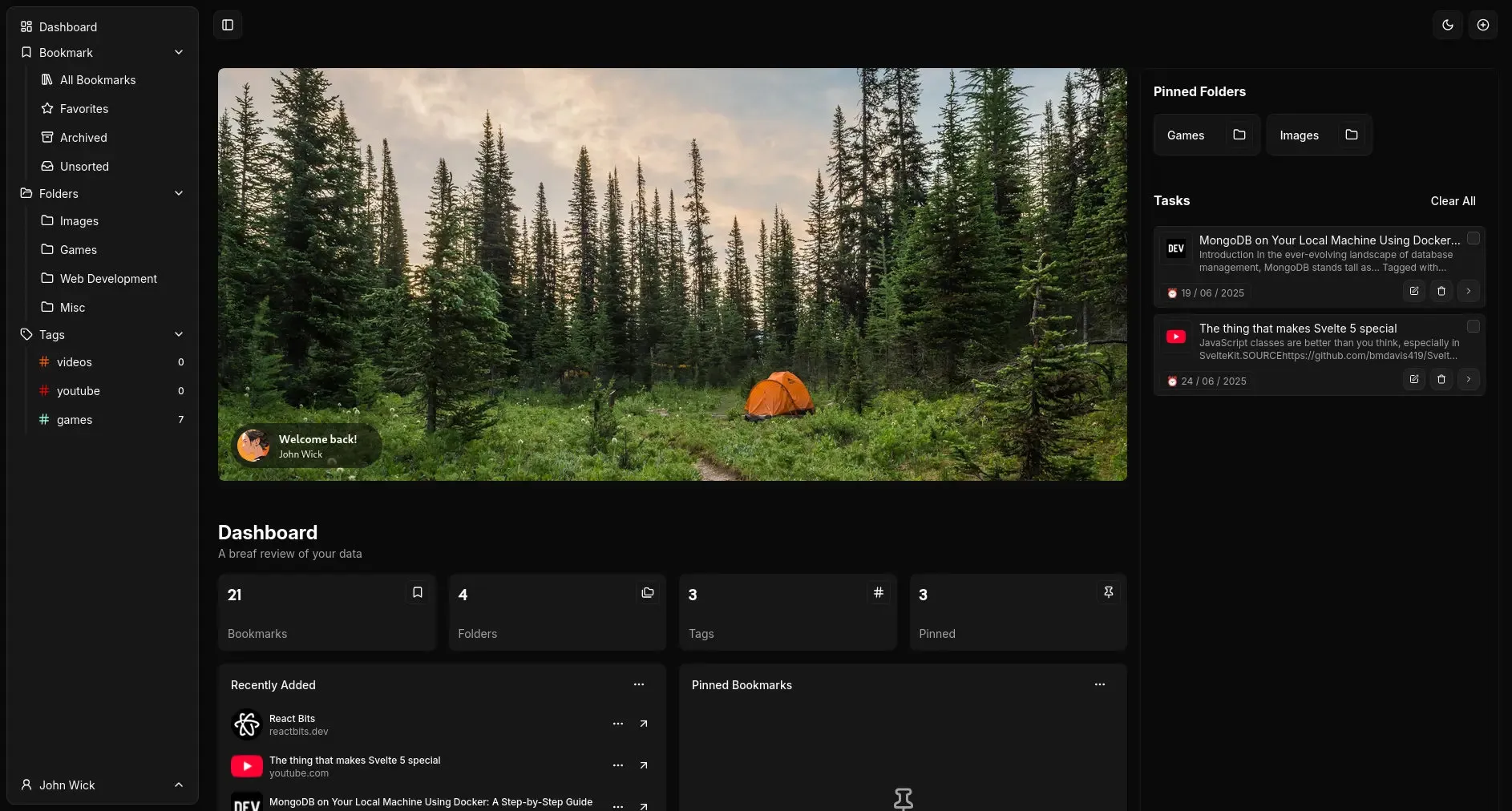 Notice the Tasks section on the right side of the page, and honestly, a lot of this page started as just “filling the space.” But even for that, I had to properly implement the Tasks feature, which also meant refactoring a bunch of code.
Notice the Tasks section on the right side of the page, and honestly, a lot of this page started as just “filling the space.” But even for that, I had to properly implement the Tasks feature, which also meant refactoring a bunch of code.
The elephant in the room was “collaborative folders,” a feature inspired by Linkwarden that I decided to implement. It required a major refactor of the codebase to overhaul data fetching and permission management. I also attempted to implement Row-Level Security (RLS), which turned into a painful experience that I still have PTSD. Having worked with Supabase before, I had a basic understanding of RLS, but I’d never dived into its intricacies. With Neon, the approach involved using JWT to authenticate users, authorize rows, and write policies. The challenge came during development, as I was using a local PostgreSQL 17 instance via a Docker image. Implementing RLS offline required installing the pgbouncer extension, but Neon uses its own pg_session_jwt, which has guides for most authentication libraries—except Better Auth. Without clear documentation, I was on my own.
I switched to an online Neon instance with a branch for development, as Neon’s neon_local Docker image serves a different purpose and doesn’t run PostgreSQL locally. Initially, JWT setup worked, but Neon suddenly threw errors, stating only ES256 and RS256 algorithms were supported. With Better Auth, any non-default JWT configuration crashed the server. After digging through GitHub issues, I found a resolved thread that pointed to a simple fix: updating the better-auth package. This took about 45 minutes to sort out. However, I later learned from Neon’s Discord server that neon_auth and Neon’s RLS are mutually exclusive, meaning no direct auth support. There might be a workaround, but after four solid days of no progress, I was exhausted and felt defeated. I’m used to solving most problems, but sometimes stepping back is the best option. Since this isn’t a multi-tenant app, RLS was arguably overkill anyway. For now, I’ve stuck with a requireAuth middleware that checks for sessions and throws an error if none are found, except for public shareable links. This works well, especially since a bookmark manager is primarily a personal app.
Things I have learned
- Building backend with Hono, understanding CORS, CSRF attacks etc.
- Implement semi from scratch Auth, from scratch never a good idea, many failed
- Cloudflare Tunnels: it’s always painful to host always for testing, and ngrok is shit
- Handling transitional emails with resend, custom domains, DNS configuration etc
- Using services like ImageKit, Cloudflare etc.. In future I’m looking forward to S3 buckets (object storage)
- Relearn pre-built solutions always better, otherwise I used to scrap with cheerio for rich link previews
- Learn how encryption works, good practices and bad practices.
- Web workers: too much fun. I used this with noble crypto operations cause it’s client site and not asynchronous
- Service Workers: Again, fun journey had to use for browser-extension and later PWA
- Improved my react skills further, I started using underrated (for a reason) hooks like
useReducer - Improved my SvelteKit skills, I’m using that for landing page for now
- Learn significance when & why you should pick ESLint, Prettier basically more mature tools, over bleeding-edge tool like Biome.js. Simple ans when you’re not pro yet
- Find out TailwindCSS v4 it’s better than v3 no matter what people says, yes it’s promoting arbitrary values but also fixed a lot of pain points as well. Corporate works are interested in learning same thing differently and they have a good excuse for that
I’m torn. Part of me wonders if I should’ve gone with Next.js as they say. But Tanstack Router? Absolute game-changer. Its routing is leagues ahead of Next.js in flexibility and control. You’ve got to try it to get why it’s so good. For my next full-stack project, I might consider Next.js or even Tanstack Start, but I’m also itching to experiment with React + Tanstack Router & Query + Elysia.js stack, all in a monorepo with tRPC. Man, programming is so goddamn fun, too much to explore and too little time. I wounder why I started so late.
What’s Next?
I’m excited about building a CLI application for this project, something I’d planned from the start. Why a CLI? I love working in the terminal, and so do many others—it’d be a blast to create a CLI that enables searching and managing bookmarks, opening up possibilities like integrating with tools such as Rofi, creating custom menus, or building widgets for Linux through low-level API calls. I’m leaning toward using Go for the CLI, which influenced my earlier switch from libsodium to noble for encryption. It wasn’t because noble is directly available in Go, but because it uses standard cryptographic algorithms compatible with Go’s crypto library. However, planning hit a snag: I’m using Better Auth for authentication, but Go lacks Better Auth support, which had me considering TypeScript for the CLI. Then, this YouTube video dropped at the right time, and it felt like the universe preventing me from ruining terminals.
Conclusion
This project taught me a lot of things, mostly how to build back-end. Maybe for the first time it was not a very good approach, but next time I guess I will get things down quicker and focus on other parts. It sometimes shocks me, how far I’ve come and still I can’t just feel I’m there yet. I’m noob as hell, but it’s fun and that’s important. Middle of the project I got depressed, and then learned that taking break is also part of programming, I was careless and spent 14 Hours just coding and exploring. It was a bad call and not a thing to flex, cause that proves I don’t probably have a life. Also I’m a fan of rice and Linux user and that adds salt to it XD. But among all other problems question is can I keep up the pace and continue with the project, yes ofc. I would like to. As long as I’m personally using it, I will maintain it, I know I will cause I do use my own start page NothingUI New Tab everyday, and maintain it.